About the ECLADATTA project
![]()
The ECLADATTA project (2023 - 2026) is a French national research project financed by the French National Research Agency (Agence Nationale de la Recherche - ANR) under grant ANR-22-CE23-0020.
ECLADATTA stands for ExtraCtion of LAtent knowledge in Documents by conjointly Analyzing Texts and TAbles.
Summary
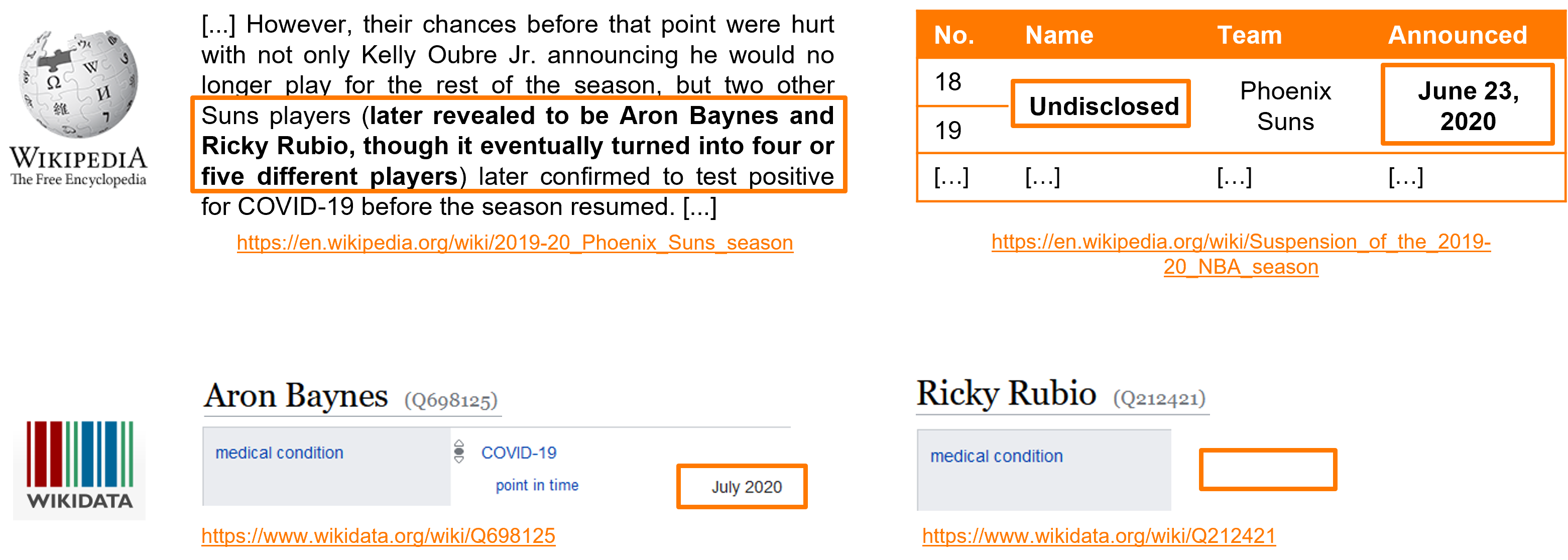
Complementarity between tables, texts, and knowledge graphs and a joint knowledge extraction and reconciliation process constitute the focus of the ECLADATTA project. Indeed, texts and tables may be related when presented in the same document or even across documents and complement each other. For example, in the figure below, a Wikipedia page about a specific NBA team mentions that two basketball players were tested positive for COVID-19, while those names are missing in a summary table from another dedicated Wikipedia page. The date indicated in the Wikipedia table could nevertheless be used to correct or complete the Wikidata entries for the two players.
The ECLADATTA project aims at leveraging this complementarity between tables, texts, and knowledge graphs to propose a joint knowledge extraction and reconciliation process. The overall and original objective of ECLADATTA is to propose new methods and to develop tools
- to assess the relatedness between tables and texts (within documents and across documents) and build on-demand text-table corpora based on a variety of filtering criteria
- to automatically extract knowledge jointly from tables and related texts
- to check the consistency of knowledge from tables, texts, and knowledge graphs
- to refine tables, texts, and general or domain-specific knowledge graphs
Team
Consortium



Associated Partner
